Поиск Google
Просмотр сохранённых в кэше Google страниц начинается так же, как и любой другой поиск Google. Когда вы ввели поисковый запрос и видите результаты, нажмите на стрелку рядом с URL-адресом и выберите опцию «Сохранённая копия» для просмотра последних сохранённых в Google версий страниц.
Когда сайт загрузился, Google уведомляет, что это устаревшая версия, и указывает дату её создания. Также есть опция просмотра только текстового варианта страница и исходного кода. Вы не сможете переходить на другие страницы и при этом оставаться в кэш-версии. Если вы попытаетесь перейти по ссылке, откроется действующая версия сайта.
Как выглядели культовые сайты раньше
Для примера посмотрим, как выглядели популярные ресурсы раньше, а именно Яндекс, Google, YouTube, Википедия и VK. Все из них с течением времени претерпели кардинальные изменения в дизайне.
Поисковик Яндекс
Поисковую систему Яндекс официально анонсировали 23 сентября 1997 года. С тех прошло более 20 лет, и сегодня это одна из самых популярных поисковых систем в мире.
В веб-архиве первая сохраненная копия датируется 6 декабря 1998 года.
На тот момент выглядел Яндекс вот так:
Поисковик Google
Поисковая система Google была основа чуть позже – в 1998 году. Сейчас это самая популярная поисковая система в мире.
Первые сохраненные копии появились в веб-архиве в конце 1998 года. Например, 2 декабря Гугл выглядел вот так:
YouTube
Youtube начал свою работу в феврале 2005 года. Первые сохраненные в веб-архиве копии появились в конце апреля 2005 года. На то время сервис имел минималистичный дизайн, и видно, что он являлся не более, чем видеохостингом:
Википедия
Википедия появилась 15 января 2001 года. Сегодня она является наиболее крупным и популярным справочником в интернете и содержит более 40 миллионов статей, которые доступны на 301 языке.
В веб-архиве первая сохраненная копия Википедии датируется 27 июля 2001 года:
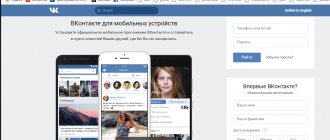
ВКонтакте
Популярная в России и других странах социальная сеть ВКонтакте была создана 10 октября 2006 года.
В веб-архиве первая сохраненная копия сайта датируется 8 ноября 2006 года. На нём видно, что сайт изначально был ориентирован на студентов и выпускников.
Wayback Machine
Существуют организации, которые пытаются сохранить историю интернета. Самой известной такой организацией является некоммерческая Internet Archive, где хранятся веб-сайты, текст, видео, аудиозаписи, программное обеспечение и изображения, которые трудно найти где-то ещё. Старые версии веб-сайта вы можете посмотреть также на Wayback Machine.
Введите URL-адрес и движок архивного поиска покажет календарь, где отображается, когда Wayback Machine сохранила эту страницу. Нажмите на дату в календаре для просмотра того, как сайт выглядел в этот день. Wayback Machine и является отличным способом изучения истории интернета.
Для чего нужно искать старые версии сайтов
Причины, по которым может быть необходимо посмотреть сайт в прошлом времени, могут быть абсолютно разными. Часто это желание погрузиться в приятную ностальгию. Например, посмотреть, как раньше выглядели популярные площадки и соцсети. Или же посмотреть, как выглядел собственный сайт несколько лет назад. К счастью, существует инструмент, который позволяет это сделать, даже если сам ресурс уже давно не доступен.
Как это возможно? Если сайт существует в интернете хотя бы пару дней, он попадает в веб-архив. Инструмент сохраняет его код, благодаря чему, можно увидеть, как он выглядел даже много лет назад.
Причины, по которым возникает необходимость посмотреть порталы в прошлом времени:
- Отслеживание истории изменений. Такая потребность может возникать у копирайтеров или журналистов для подготовки нового контента. Также это может быть нужно для анализа конкурентов: можно проследить путь их развития и увидеть допущенные ошибки.
- Восстановление ресурса. Если пользователь забыл продлить домен или не сделал бэкап, веб-архив будет отличным вариантом восстановления.
- Поиск уникального контента. Если площадка больше не доступна, её контент становится уникальным. Можно использовать его полностью или частично, предварительно проверив уникальность.
- Увидеть необходимый контент, если страница уже недоступна. Например, пользователь добавил площадку в закладки, а через время оказалось, что её больше нет. Тогда посмотреть её содержимое можно только с помощью веб-архива.
Расширения для браузеров
Существуют расширения для браузеров на все случаи жизни, в том числе и для доступа к кэшированной версии сайта.
Добавьте в Chrome расширение Web Cache Viewer и нажмите правой кнопкой мыши на любой странице для просмотра версии из Google или Wayback Machine. Расширение под названием View Page Archive & Cache для Chrome или Firefox идёт ещё дальше и позволяет смотреть кэшированные версии веб-страниц из многочисленных поисковых движков, таких как Bing, Baidu, Yandex.
Можно ли восстановить сайт из вебархива?
При потере данных, восстановить свой сайт можно с помощью сайта https://webarchiveorg.ru/. Для этого нужно:
- ввести URL-адрес;
- выбрать нужный год, месяц и число;
- нажать кнопку «Восстановить сайт».
Услуга является платной, поэтому перед восстановлением рекомендуется ознакомиться с тарифами. Точная стоимость зависит от количества сайтов и его страниц.
Сохраненные копии страниц – это не то, что находится в индексе
Издавна SEO-специалисты используют сохраненную копию страницы в поисковике для анализа индексации произведенных на странице изменений. Однако еще четыре года назад я заметил, что в Яндексе сохраненная копия может не совпадать с той версией страницы, которая реально находится на данный момент в поисковом индексе и используется в ранжировании. Сегодня мне хотелось бы проверить, можно сейчас ли доверять сохраненной копии Яндекса. Ну, и заодно посмотреть, как с этим обстоят дела у его основного конкурента на отечественном рынке поиска – Google.
Для анализа мне понадобится страница, на которой публикуется текущая дата. Сопоставляя дату, которая находится в сохраненной копии с датой, по которой эта страница находится в поисковике, и которая может показываться при этом в ее сниппете, можно сделать вывод о соответствии версии страницы, демонстрируемой в сохраненной копии, и версии страницы, находящейся в поисковом индексе. Для нашей цели как нельзя лучше подойдет главная страница Яндекса.
Итак, анализируем сначала ситуацию в самом Яндексе, найдя главную страницу Яндекса с помощью документированного оператора url: запросом url:yandex.ru и открыв ее сохраненную копию. Находим в ней дату (на момент анализа – это «25 февраля, понедельник, 22:23»):
Итак, попробуем найти по точной текстовой фразе с этой датой в Яндексе его главную страницу. Увы, но сделать этого не удалось. Мы получаем сообщение, что точного совпадения не нашлось:
Получается, в поисковом индексе находится версия главной страницы Яндекса от другой даты. С помощью несложных манипуляций с изменением даты в поисковой фразе убеждаемся, что в индексе содержится более ранняя версия главной страницы Яндекса.
К сожалению, Яндекс не соизволил нас порадовать показом текстового соответствия в сниппете (видимо, считая данный текст служебным и малозначимым), однако отсутствие фразы «Точного совпадения не нашлось» красноречиво свидетельствует о том, что именно данная фраза содержится в той версии страницы, что находится на данный момент в поисковом индексе:
Более того, можно убедиться в том, что сохраненная копия в Яндексе может иметь несколько версий, показываемых попеременно. Так, обновляя страницу с сохраненной копией главной страницы в Яндексе, мы можем время от времени увидеть другую ее версию с другой датой (в моем случае – «24 февраля, воскресенье 22:37»), но все равно не совпадающей с той, по которой страница находится в индексе:
Итак, ситуация в Яндексе не изменилась. Сохраненная копия по-прежнему не совпадает с той, что находится в индексе и участвует в ранжировании.
Ну, а что же по этому поводу думает Google? Сохраненную копию страницы можно посмотреть напрямую с помощью оператора cache. Делаем в Google запрос cache:yandex.ru, получаем сохраненку и находим в ней дату:
К сожалению, оператор site: в Google, в случае его применения к главной странице сайта, показывает выдачу по всему сайту, и по запросу по дате без времени мы получаем достаточно много страниц с сайта в выдаче (с сервиса Яндекс.Погода и т.п.), что затрудняет анализ. Но добавив в запрос время, убеждаемся, что по точной фразе выдача пуста:
Для того, чтоб облегчить нахождение даты версии, находящейся в индексе, воспользуемся одним интересным приемом.
Есть в Google оператор получения сведений о странице info:, который показывает сниппет указанной страницы в случае наличия ее в индексе. К сожалению, этот оператор не желает корректно работать в связке с поисковым запросом, т.е. не является аналогом оператора site:. Однако, если справа от этого оператора использовать какой-либо термин, то в случае наличия его точного вхождения в тексте страницы, мы можем увидеть сниппет с подсветкой этого термина.
Используя в качестве такого термина название текущего месяца в соответствующем падеже, получаем отображение даты в сниппете, и убеждаемся в том, что она не совпадает с той, что содержится в сохраненке:
Проверим с помощью запроса по точной фразе, что в поисковом индексе действительно находится версия страницы с указанной датой:
Любопытно, что в Яндексе версия анализируемой страницы в сохраненной копии свежее версии в индексе, а в Google – наоборот.
Итого в результате несложного анализа убеждаемся в том, что ни в Яндексе, ни в Google нельзя быть уверенным в том, что версия страницы, показываемая в сохраненной копии, используется для ранжирования. И этот факт обязательно необходимо учитывать при анализе поисковой выдачи, дабы избежать ложных выводов.
Как посмотреть веб-архив?
В том, как посмотреть веб-архив, нет ничего сложного. Для этого достаточно знать адреса нужного ресурса. Необходимо зайти на официальную страницу archive.org и ввести URL нужного сайта. После этого, система выдаст Вам всю имеющуюся у неё информацию об этом ресурсе.
С помощью использования веб-архива, можно проследить развитие сайтов компаний, найти информацию, пропавшую из доступа. Возможно, через некоторое время люди воспользуются им, чтобы узнать, для чего нужен и что такое челлендж в 2021 году. Именно за это, за возможность узнать культурно-историческую составляющую интернета, проекту и была присвоена награда.
Как пользоваться веб-архивом?
В том, как пользоваться веб-архивом, нет ничего сложного. Для того, чтобы использовать его, достаточно перейти на соответствующий сайт archive.org и в поиске вести адрес нужного сайта. После непродолжительного времени, архив выдаст информацию об имеющихся сохранениях этого ресурса.
Например, с помощью этого можно найти информацию с сайта, который по каким-либо причинам перестал существовать. Так же веб архив поможет найти информацию со страниц, даже если она была удалена. Это особенно важно для поиска удачных примеров сторителлинга лет. Рассмотрим подробнее, как посмотреть архив.